MySQL - Intro
Hvad skal du lære
Niveau C
I denne introduktion skal du lære noget om databaser og om hvordan man opretter, ændrer i og anvender dem. Du vil arbejde med at:
- Installere MySQL/phpMyAdmin
- Lære om datatyper
- Designe en database
- Oprette en database
- Oprette forbindelser mellem tabeller
- Ændre på data
Installere MySQL/phpMyAdmin
Vi vil anvende MySQL database ved hjælp af webinterfacet phpMyAdmin. MySQL er en meget anvendt database på internettet og er den database der ligger bag mange webapplikationer.
Vi vil anvende XAMPP til at installere en webserver med alle relevante programmer
Vide noget om datatyper
Når man arbejder med data anvender man forskellige typer af data. Det kan være værdier (tal man skal kunne regne med), tekststrenge (tekst eller tal der skal arbejdes med) eller datoer (tidsværdier)
Designe en database
Du vil lære at designe databaser ved hjælp af ER-diagrammer. Diagrammerne støtter en når man skal oprette databasen og giver et overblik over hvor det kan være fornuftig at sætte forbindelser mellem data.
Oprette en database
Du vil lære at anvende phpMyAdmin til at oprette, indsætte og redigere i databaser. PhpMyAdmin er et meget anvendt brugerinterface til netværksbaserede databaser.
Oprette forbindelser mellem tabeller
Du vil lære at oprette forbindelser mellem tabeller i en database, for at sikre dig mod datatab og for at kunne undgå redundans (gentagelser).
Ændre på data
Du vil lære at ændre på data i tabeller
Databaser
Databaser er grundlæggende en samling af struktueret data. Disse databaser deler vi op i det vi kalder flade databaser og relationsdatabaser.
Flade databaser
Al data er i én tabel. Det er en fordel hvis det kun er få data vi snakker om. Det kan f.eks. være en almindelig tabel i et tekstbehandlingsprogram eller et regneark. F.eks. en telefonliste, eller tabel hvor man kan se sammenhængen mellem postnummer og by. Disse tabeller kan stå helt for sig selv.
Du kan se et eksempel på en flad database her:
| Tabel 1 - Klasser, mentorer og elever | |||
|---|---|---|---|
| Klasse (Nøgle) | Mentor | Navn | Antal elever |
| 1a | tj | Thomas Jensen | 17 |
| 2a | tj | Thomas Jensen | 22 |
| 3a | tj | Thomas Jensen | 21 |
| 1b | ba | Bent Andersen | 16 |
| 2b | ba | Bent Andersen | 24 |
| 3b | ba | Bent Andersen | 22 |
| 1x | cc | Christina Carlsen | 28 |
| 2x | cc | Christina Carlsen | 31 |
Relationsdatabaser
Data er fordelt i flere tabeller, hvor man har lavet relationer (forbindelser) mellem dem
Forestil dig en database, hvor man skal have et overblik over de data der er på elever, lærere, klasser, personale, lokaler osv. Her vil det være en fordel at have en tabel med by og postnumre. Det vil betyde at databasen selv kan finde det bynavn, der er hører til de enkelte postnumre, sådan at selve bynavnet kun står en gang. Det sparer både indtastninger, men også plads i databasen (redundans).
Det betyder også, at man kan bruge nogle rækker som kontrolinstanser. F.eks. vil et forkert postnummer kunne udløse en advarsel, fordi det ikke eksisterer. Eller man vil kunne sikre sig mod at der bliver slettet data som andre tabeller er afhængige af.
Man kan ikke blot forbinde tabeller i den enkelte database med hinanden, men også forbinde forskellige databaser med hinanden, sådan at man kan udnytte data fra flere kilder.
Herunder er et eksempel som det ser ud med phpMyAdmins designervindue:
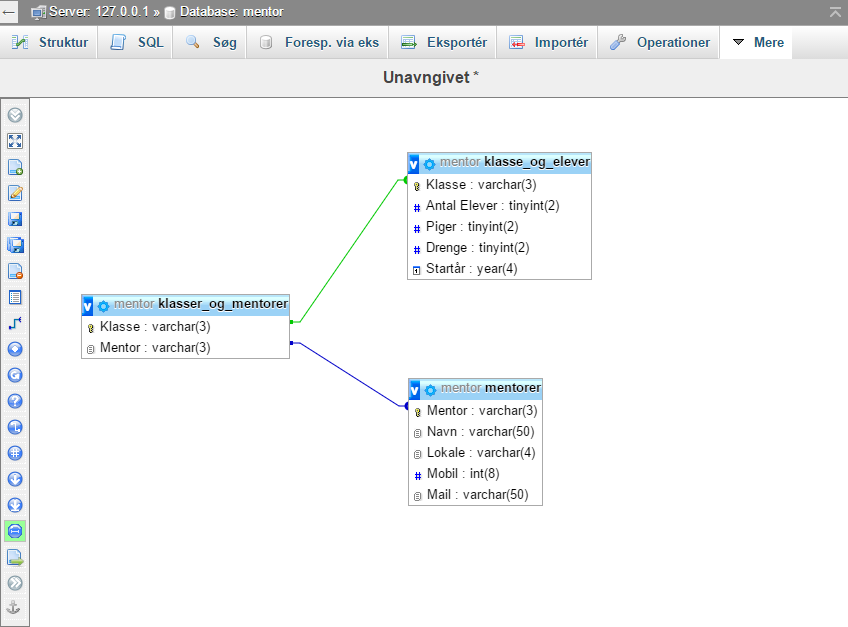
Redundans
Redundans er et fint ord for data der er tilstede mere end en gang.
I det ovenstående tilfælde nævner jeg en tabel med bynavn og postnummer. Hvis man ikke havde den tabel ville alle tabeller med adresser skulle indeholde både bynavn og postnummer. Et af disse felter ville altså være redundant. Det vil betyde at man skal bruge mere tid på at indtaste data, databasen fylder mere og databasen skal sortere i flere data for at finde sine resultater. Alt sammen noget der ikke er effektivt og koster både tid og penge.
En god database er designet så man undgår redundans, og den proces hedder normalisering (http://www.vidas.dk/IT/MySQL_database_normalisering.html). Det er et område der hører til på IT B.
Grundbegreber
Database
En database er en struktureret samling af data, som er sat op i tabeller, med rækker og kolonner. Ved hjælp af kommandoer kan man manipulere med, søge i og sortere data.
En relationel database indeholder flere tabeller, som kan sammenkædes og kombineres.
Tabel
En tabel er en samling af data der er struktureret indefor et afgrænset område f.eks: medarbejdere og deres kontaktoplysninger
Post - række
En post er de enkelte data rækker f.eks. den enkelte medarbejder og dennes kontaktoplysninger
Felt
Et felt er de enkelte data i en post f.eks. medarbejderens mail
Datatype
For at gemme og strukturere data skal der for hvert felt angives hvilken type data det indeholder. Det kan f.eks. være et tal, tekst eller tidsformat.
Nøgler og indeks
For at felter i tabellerne kan indgå relationer mellem hinanden skal de være synlige for databasen. Det gøres ved at indeksere felterne. Det svarer til at der er et katalog, der angiver hvor de enkelte felter er. Alle felter kan indekseres, men man bør kun indeksere de felter der skal anvendes til at lave relationer med.
Her vil vi anvende 3 typer
- Primær nøgle
- Indekserede poster
- Unikke poster
Primær nøgle
Alle tabeller skal indehold en post der kun har unikt indhold, altså indhold der kun forekommer en gang. Det er denne post MySQL bruger til at administrere tabellen.
Det kan være en fordel at lade dette felt være noget som identificere den enkelte post, og det kan f.eks. være et brugernavn, kunde ID, telefonnummer, mail osv.
Indekserede felter
Når en tabel er oprettet kender databasen kun til den post der er primærnøgle. Vil man skabe relationer mellem andre poster i tabellerne, skal de indekseres.
Unikke-felter
Unikke felter er som indeks, men kræver at hver post er unik. Ved at indeksere et felt med værdien unik, kan to poster ikke have samme værdi. På den måde kan man sikre sig, at to poster ikke har samme telefonnummer, mailadresse, firmanavn osv. Databasen vil sørge for at posten er unik.
Fremmednøgler
Fremmednøgler er felter som har forbindelse til primærfelter, og hvor der er sat en binding op imellem dem. I praksis gøres det ved at indeksere et felt, så det gøres tilgængeligt for databasen.
Fremmednøgler er afhængige af deres primærnøgler. Dette kan bruges til at opdatere felter, sådan at hvis primær nøglen ændres, så vil fremmednøglen også blive ændre. Det kan også anvendes til at sikre, at man ikke sletter en primærnøgle der er i anvendelse et andet sted i databasen.